Le Kerberoasting avec PowerShell
Comprendre et mener une attaque Kerberoasting sur un compte avec un ServicePrincipalName
Bon, on va être franc : PowerShell a beau avoir plein de qualité, la performance n’en fait pas partie, et elle peut varier considérablement en fonction de la façon dont vous écrivez et exécutez vos scripts.
Dans cet article, nous plongerons dans l’univers de la performance en PowerShell. Nous allons explorer des astuces, des meilleures pratiques et des techniques avancées pour maximiser l’efficacité de vos scripts. Ce guide vous aidera à comprendre comment tirer le meilleur parti de ce langage, en garantissant des scripts plus rapides, plus efficaces et moins gourmands en ressources.
On commencera donc par des conseils généraux, simples à comprendre et facile à implémenter pour ensuite se concentrer sur des techniques plus avancées qui nécessitent de se mettre à jour sur votre syntaxe ou sur les méthodes que vous avez toujours utilisées.
Tous les filtres ne se valent pas ! Une règle de base peut être facilement utilisée : faire les filtres les plus stricts (ceux qui éliminerons le plus d’objets) en amont. Moins votre collection sera grande, plus votre script sera performant.
Point bonus : si votre collection est composée de PSCustomObject, évitez de garder des propriétés inutiles. L’idée est de raisonner en termes de “poids total” de votre collection : ce qui importe, c’est le nombre d’objets et le nombre de propriétés par objet.
De manière générale, une requête pour obtenir 10 000 utilisateurs est moins coûteuse que 10 000 requêtes d’un seul utilisateur.
Morale de l’histoire : faire une grosse requête pour rechercher ensuite à l’intérieur du résultat plutôt que de faire une requête à chaque fois.
Pour Microsoft Graph : des rapports CSV sont disponibles (notamment pour les statistiques d’usage des boîtes aux lettres) et permettent de gagner beaucoup de temps par rapport à des requêtes individuelles, beaucoup plus coûteuses.
N’importe quel type d’affichage dans une console va vous coûter du temps de traitement ! Que ce soit du Format-Table, du Write-Progress ou du Write-Output : rien à faire, vous perdrez en performance.
Cependant, avant de tomber dans le dogmatisme je tiens à préciser quelque chose d’important : la perte en temps vaut probablement le coup, et ça pour plusieurs raisons :
Write-Output de votre script, car il y a de grandes chances pour ça ne soit pas la cause principale.Pour optimiser votre code, le plus important est d’identifier le goulot d’étranglement. Pour ça, vous pouvez utiliser la commande Measure-Object qui va mesurer le temps d’exécution du code qui va se trouver entre les deux accolades. Certaines commandes sont plus gourmandes que d’autres (notamment les requêtes API, les cmdlet Exchange et Microsoft Graph) et le Measure-Object peut vous permettre de calculer précisément le temps d’exécution global, pour faire ensuite une belle barre de progression avec Write-Progress (notamment via le paramètre -SecondsRemaining).
Voici un petit script qui permet de mesurer la durée moyenne d’exécution d’une commande ou d’un script PowerShell sur 100 itérations :
$stats = foreach ($_ in 1..100) {
Measure-Command -Expression { Get-LocalGroup }
}
$stats | Measure-Object -Property 'TotalSeconds' -Average
Vous aurez beau optimiser votre code comme jamais et suivre toutes les bonnes pratiques possibles, un script exécuté avec Windows PowerShell 2.0 sera toujours moins performant qu’un même script exécuté en PowerShell v7. Les versions les plus récentes embarquent toujours leurs lots d’améliorations, autant au niveau des performances qu’au niveau des fonctionnalités.
Voici un comparatif de temps de traitement sur plusieurs scripts différents, exécutés sur la même machine, sur des données locales uniquement (moyenne sur 100 exécutions) :
| Version | Script n°1 | Script n°2 | Script n°3 |
|---|---|---|---|
| PowerShell 2.0 | 65ms | 70ms | 85ms |
| PowerShell 5.1 | 49ms | 49ms | 70ms |
| PowerShell 7.3 | 15ms | 10ms | 14ms |
On observe PowerShell 7.3 fonctionne en moyenne quatre fois plus rapidement que son ancêtre PowerShell 2.0, avec un script identique (donc sans utiliser la parallélisation).
Pour suivre les dernières nouveautés de PowerShell : Overview of what’s new in PowerShell | Microsoft Learn
Je le connais, vous le connaissez, tout le monde le connait et l’utilise. Et pourtant, c’est la méthode la moins performante que l’on puisse choisir !
$array = @()
1..10 | % { $array += $_ }
Comment ça marche ? La syntaxe très simple cache en fait un fonctionnement assez complexe.
Avec @(), vous allez créer une collection de taille fixe avec une capacité maximum de 0 élément. Comment agrandir la collection alors ? En tout cas on ne peut pas y ajouter d’éléments avec la méthode .Add() puisque celle-ci nous donne l’erreur : Exception lors de l’appel de «Add» avec «1» argument(s): «La collection était d’une taille fixe.».
On va donc utiliser l’opérateur +=, qui ne va pas ajouter un élément à la collection existante (puisque ce n’est pas possible) mais plutôt :
En bref : un processus bien plus complexe que la syntaxe ne peut le laisser deviner. Pour résumer, le += pourrait être expliqué avec la syntaxe suivante :
$array = @()
1..10 | % { $array = $array + @($_)}
La solution est donnée dans l’article de blog cité plus haut, mais pour faire une version rapide, on peut retenir deux options :
List<T>Voici un exemple rapide d’utilisation pour les deux méthodes :
# List<T>
$list = [System.Collections.Generic.List[int]]@{}
1..100 | ForEach-Object { $list.Add($_) }
# Aspiration via pipeline
$list = 1..100 | ForEach-Object { $_ }
Voici un tableau qui récapitule vos options pour la création d’un tableau :
| Méthode | Compatibilité | Performance | Simplicité | Fonctionnalités |
|---|---|---|---|---|
@() |
Bonne | Mauvaise | Moyenne | Moyenne |
List<T> |
Mauvaise | Moyenne | Mauvaise | Bonne |
| Aspiration via pipeline | Bonne | Bonne | Bonne | Moyenne |
Et si ça vous intéresse, je ne peux que vous recommander de lire l’article original : Building Arrays and Collections in PowerShell | Clear-Script
On lit souvent que foreach est plus performant que ForEach-Object, ce n’est pas tout à fait vrai : il s’agit simplement d’une utilisation différente.
La boucle foreach est en effet plus performante si toutes les données à traiter ont déjà été récupérées.
L’avantage et l’inconvénient du ForEach-Object, c’est qu’il s’utilise avec un pipeline. Le pipeline (qui pourrait être traduit grossièrement en tuyau) permet d’envoyer de la donnée dès qu’elle est disponible. Donc si vous faites une requête avec 10000 objets en résultat, le traitement via le pipeline permettra de commencer le travail dès que le premier objet est reçu.
Vous pouvez visualiser la différence avec les scripts suivants :
function Test-Pipeline {
1..100 | ForEach-Object { $_ ; Start-Sleep -Milliseconds 100 }
}
Test-Pipeline | ForEach-Object {
Write-Progress -Activity "Using 'ForEach-Object'" -PercentComplete $_
}
foreach ($_ in (Test-Pipeline)) {
Write-Progress -Activity "Using 'foreach()'" -PercentComplete $_
}
En résumé : si la liste de données à traiter est instantanément disponible (un fichier CSV par exemple), alors préférez l’utilisation de foreach. Si les données arrivent au fur et à mesure (comme pour une requête API par exemple), alors préférez le pipeline et ForEach-Object.
Pour tout savoir sur le pipeline : Understanding PowerShell Pipeline | PowerShell One
Avec l’arrivée de PowerShell v7, la commande ForEach-Object récupère un nouveau paramètre : -Parallel. Ce paramètre permet (comme son nom l’indique) de paralléliser et donc de diviser le temps de traitement par le nombre d’instances (en général : le nombre de CPU +1).
Si vous pouvez avoir accès à ce paramètre, vous pouvez l’utilisez pour diminuer le temps d’exécution de vos boucles ForEach-Object. Attention cependant : la parallélisation n’est pas “gratuite”, et initier une nouvelle instance pour traiter un objet a un coût.
Ainsi, sur certaines boucles très rapides, vous ne verrez pas d’amélioration voir pire : une dégradation des performances. Si vous voulez vous amusez, vous pouvez tester la différence entre ForEach-Object et ForEach-Object -Parallel sur des commandes simples avec la fonction suivante :
function Test-Parallel {
param(
[string]$Command = '$PSItem',
[int]$Iteration = 100
)
$scriptA = "(Measure-Command { 1..$Iteration | ForEach-Object { $Command } }).TotalMilliseconds"
$scriptB = $scriptA -replace 'ForEach-Object','ForEach-Object -Parallel'
$statRef = Invoke-Expression $scriptA
$statDif = Invoke-Expression $scriptB
$dif = $statRef/$statDif
if ($statRef -lt $statDif) {
[int]$dif = (1-$dif)*100
$slowerOrFaster = 'rapide'
} else {
[int]$dif = ($dif-1)*100
$slowerOrFaster = 'lente'
}
Write-Host "La boucle sans parallélisation est $dif`% plus $slowerOrFaster que la boucle avec parallélisation"
}
Pour supprimer l’affichage ou la récupération du résultat d’une commande, quelle est la commande la plus performante : Out-Null ou $null = ?
Get-Command | Out-Null
# vs.
$null = Get-Command
Réponse : C’est la commande $null = est 25% plus rapide, mais le gain en performance sur un script de la vraie vie reste minime.
Lorsqu’il s’agit de créer un nouveau PSCustomObject, quelle est la méthode la plus performante entre New-Object et [PSCustomObject]@{} ?
New-Object -TypeName 'PSCustomObject' -Property @{}
# vs.
[PSCustomObject]@{}
Réponse : Je n’ai trouvé aucune différence de temps de traitement entre les deux syntaxes. Je conseillerai tout de même d’adopter la syntaxe la plus moderne qui reste plus simple à comprendre et à lire.
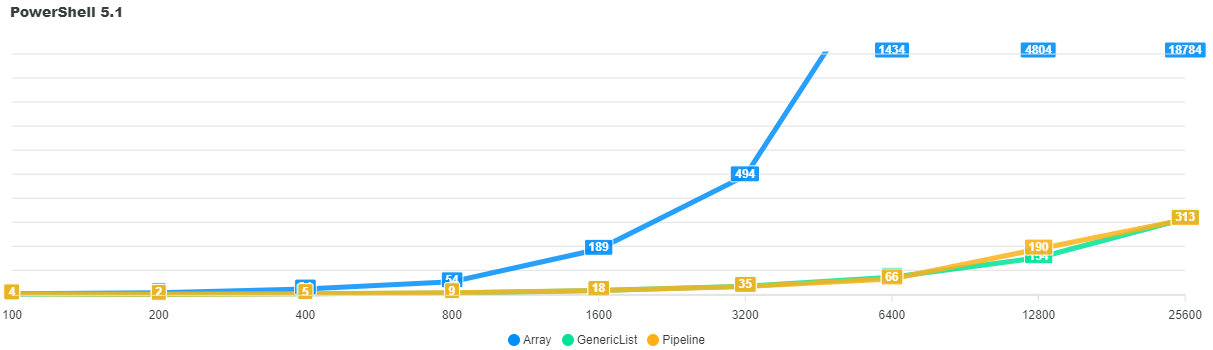
Ici on retrouve le cas évoqué un peu plus tôt, avec un comparatif entre l’array classique, le GenericList et le Pipeline. La comparaison se fait sur plusieurs tailles de collections, en PowerShell 5.1 et PowerShell 7.4.
$array = @()
1..10000 | % { $array += $_ }
# vs.
$array = [System.Collections.Generic.List[int]]@()
1..10000 | % { $array.Add($_) }
# vs.
$array = 1..10000 | % { $_ }
Réponse pour PowerShell 5.1 : Ex-aequo entre GenericList et Pipeline, les deux méthodes se valent.
| Taille | Array | GenericList | Pipeline |
|---|---|---|---|
| 100 | 4 ms | 4 ms | 4 ms |
| 200 | 9 ms | 3 ms | 2 ms |
| 400 | 25 ms | 4 ms | 5 ms |
| 800 | 55 ms | 8 ms | 9 ms |
| 1 600 | 190 ms | 19 ms | 18 ms |
| 3 200 | 494 ms | 36 ms | 35 ms |
| 6 400 | 1 435 ms | 74 ms | 66 ms |
| 12 800 | 4 805 ms | 154 ms | 190 ms |
| 25 600 | 18 784 ms | 317 ms | 314 ms |
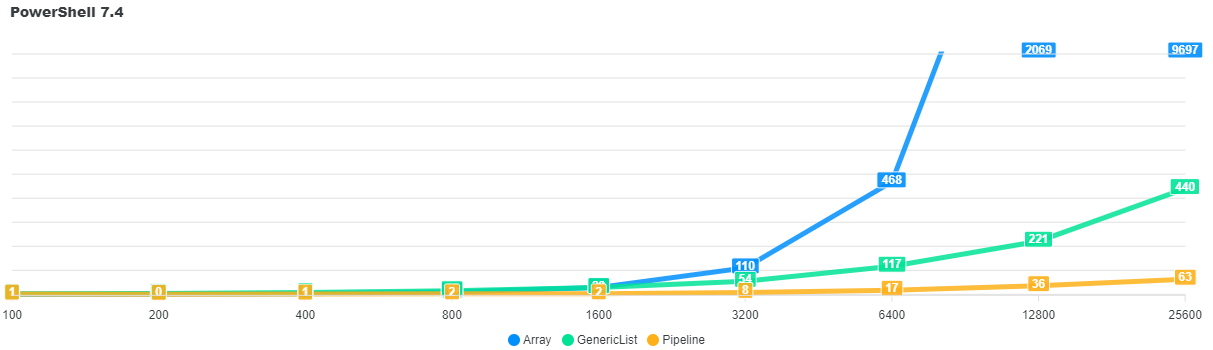
Réponse pour PowerShell 7.4 : Le gagnant est le Pipeline qui tire parti des dernières améliorations de performance apportées avec PowerShell 7+.
| Taille | Array | GenericList | Pipeline |
|---|---|---|---|
| 100 | 1 ms | 4 ms | 2 ms |
| 200 | 1 ms | 4 ms | 1 ms |
| 400 | 3 ms | 9 ms | 1 ms |
| 800 | 11 ms | 15 ms | 2 ms |
| 1 600 | 29 ms | 28 ms | 3 ms |
| 3 200 | 111 ms | 54 ms | 9 ms |
| 6 400 | 469 ms | 118 ms | 18 ms |
| 12 800 | 2 069 ms | 222 ms | 36 ms |
| 25 600 | 9 698 ms | 440 ms | 64 ms |
La déduplication d’une liste est en général un processus assez gourmand en ressources et qui peut prendre plusieurs secondes (voir même minutes en fonction de la taille de la liste). Pour gagner du temps de traitement, quelle est la commande la plus performante ?
1..10000 -replace '0','' | Select-Object -Unique
# vs.
1..10000 -replace '0','' | Sort-Object | Get-Unique
# vs.
1..10000 -replace '0','' | Sort-Object -Unique
Réponse : Voici le temps de traitement moyen sur dix exécutions :
| Méthode | PowerShell 5.1 | PowerShell 7.4 |
|---|---|---|
Select-Object |
5471 ms | 2282 ms |
Get-Unique |
307 ms | 85 ms |
Sort-Object -Unique |
155 ms | 81 ms |
Le grand gagnant est donc Sort-Object -Unique, qui est jusqu’à 35 fois plus rapide que la méthode la plus lente.
Le filtrage est très utilisé en PowerShell et il est souvent responsable de “bottlenecks”. Quelle est donc la façon la plus rapide de filtrer une collection : Where-Object ou la méthode plus complexe GetEnumerator.Where() ?
$list | Where-Object {$_.Property -eq $value}
# vs.
$list.GetEnumerator.Where({$_.Property -eq $value})
Réponse : Pour tester les deux filtres, j’ai réalisé un script qui doit faire 500 recherches différentes dans une collection d’environ 15 000 objets. Mes résultats montrent que Where-Object est deux fois plus lent que la méthode GetEnumerator.Where().

Ingénieur systèmes spécialisé dans les infrastructures, les technologies et l'écosystème Microsoft. Je travaille depuis 2017 sur les questions de gestion d'identité, d'outils collaboratifs et d'automatisation.
Comprendre et mener une attaque Kerberoasting sur un compte avec un ServicePrincipalName